C 语言
基础知识
程序设计
从本质上讲,计算机实际上是一种相当死板的装置,它仅仅能够按照人们提供给它的指令运行。计算机系统能够执行的基本命令的集合,通常称为该计算机的指令集。
为了使用计算机解决某个问题,我们必须使用计算机的基本指令描述这个问题的解决方法。所谓计算机程序,实际上也就是解决某个具体问题的计算机指令集合。按照计算机科学的术语,解决某个具体问题的方法被称为算法(algorithm)。一般来讲,如果我们需要使用计算机解决某个问题,首先需要找到解决该问题的算法,再用一段计算机程序来表达这个算法。
如判断某个数字是奇数还是偶数,我们可以采用下面的算法:用这个数字除以2,如果余数时0,那么这个数字是偶数,否则这个数字是奇数。有了算法以后,我们就可以再特定的计算机上,采用该计算机所能接受的指令来实现这个算法。这些指令可以是某种特定的计算机编程语言,如 Visual Basic,Java,C++或者C。
高级编程语言
最早的计算机只能理解二进制形式的指令,这些指令通常直接操作内存的某个地址。这种形式的指令被称为机器语言。第二代编程语言——汇编语言(Assembly Language)允许程序员水用稍微高级一些的指令形式。因为计算机只能理解二进制形式的指令,所以人们使用一个特殊的程序——汇编器(Assembler),把汇编语言的程序翻译为具体的机器语言。
汇编语言使用的符号与计算机的二进制指令实际上是一一对应的。正因为如此,汇编语言被看作时低级语言。为了使用低级语言编写程序,程序员们必须学习某个特定的计算机系统的指令集。由于不同的计算机系统,其指令集常常是不同的,因此使用低级语言编写的程序不具备可移植性。
为了克服低级语言的缺点,人们发明了高级语言。高级语言通常有一套特定的语法,这个语法与具体的计算机系统无关。人们只需要针对特定计算机系统开发一个特殊的程序,该程序将高级语言编写的程序翻译为特定计算机系统能够理解的机器指令。这种计算机程序称为编译器(compiler)
操作系统
操作系统就是控制计算机所有操作的程序。例如,计算机系统所有的输入输出操作(也称为 I/O 操作)都要通过操作系统来完成。操作系统必须管理计算机的所有资源,还要负责运行呢所有的程序。
Unix 是一种相当独特的操作,因为 Unix 的开发主要使用了高级语言 C,而且在开发这个操作时,它的设计者使它尽量独立于底层硬件环境,因此 Unix 就可以相对轻松地移植到多种计算机系统中。它拥有很多变种,能运行在多种计算机系统上,如 Linux 或者 Mac OS。
编译程序
编译器也是一个程序。编译器可以分析使用高级语言编写的程序,然后把它翻译成特定你的计算机系统能够执行的指令。
下图显示了在 Unix 操作系统中,输入、编译和执行一个 C 语言程序所需要的典型步骤,以及在 Unix 命令行下需要输入的典型命令。
- 要编译一个使用高级语言编写的程序,我们首先要把这个程序输入到计算机文件中。虽然在不同的计算机系统中,命名文件的习惯有所不同,但从总体上来说,文件名的选取还是由使用者决定。一般来讲,包含 C 语言程序的文件以 “.c” 两个字母作为文件名的结尾。因此,文件名
main.c对于我们正在使用的计算机来说,可能就是一个合法的 C 语言程序文件名。 - 我们通常文本编辑器把 C 语言编写的程序输入到计算机系统的文件中。我们可以使用 vi(Unix 系统中一种编辑器)。使用稳步编辑器生成的文件包含了 C 语言程序的原始形式,因此通常称为源文件(source file)。程序一旦输入到源文件中,我们就可以着手来编译它了。
- 为了开始编译输入的源文件,我们需要让计算机执行特定的命令。当我们再命令行中输入这个编译命令时,还必须在后面跟上源文件的名字。在 Unix 操作系统中,开始编译 C 语言源文件的命令是
cc。如果使用的是 GNU C 编译器,那么启动编译器的命令则是gcc。在命令行上输入下面的命令:(mac 就是 unix 系统的变种)
cc main.c
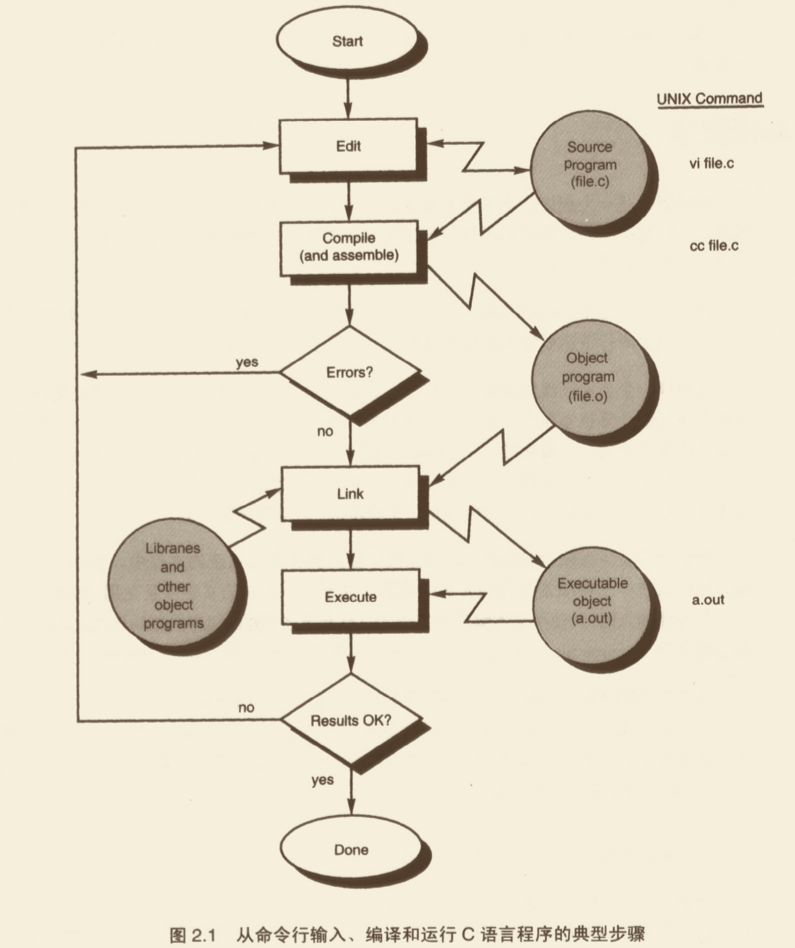
- 在编译的第一阶段,编译器首先检查源程序的每一条语句,看它是否符合语言的语法和词法。如果编译器在这个阶段发现了错误,便会将这些错误报告给用户,然后停止运行。程序员必须实用文本编辑器改正这些错误,并重新开始编译。这一阶段发现的典型错误通常包括不匹配的括号(词法错误),或者实用了未定义的变量(语法错误)等。
- 当程序中所有的语法和语义错误都被改正以后,编译器就会把高级语言编写的源程序翻译为较低级的形式。在绝大多数计算机系统中,这些高级语言程序通常首先被翻译为汇编语言程序,这些汇编语言程序完成的功能与高级语言程序相同。
- 源程序被翻译为对应的汇编语言程序之后,编译器还需要将这些汇编语言程序翻译成为实际的机器指令。这个步骤有时需要借助汇编器完成。在绝大多计算机系统中,编译器通常会自动调用汇编器。
- 汇编器读入编译器生成的汇编语言程序,将其翻译为二进制格式的代码,这种代码被称为目标码。汇编器将这些生成的目标码保存在目标文件中。在 Unix 操作系统中,目标文件通常使用与源文件相同的文件名保存,但是文件名的结尾不是
.c,而是.o。在 Windows 操作系统中,目标文件的结尾则是.obj。 - 生成目标文件以后,我们就可以进行下一个步骤——“连接(Link)”了。如果我们实用的 Unix 平台下的
cc命令或者gcc命令的话,这一步骤也是自动的。连接的主要作用呢是将目标代码转化为具体的计算机系统呢上实际的可执行程序。如果我们在源程序中调用了其他程序的话,那么连接程序就会把这些程序的目标代码和我们的程序的目标代码连接在一起。如果我们的程序还实用了系统提供的库函数,这些库函数的代码也会被连接到最后生成的可执行程序中。
编译和连接一个程序的过程也常常被称为构建(building)。
- 连接步骤生成的可执行代码被连接器(Linker)保存在系统的可执行文件中。在 Unix 环境中,连接器生成的可执行文件,其默认文件名是
a.out。在 Window 操作系统中,这个可执行文件的名字通常与源文件名字相同,但是其文件名的结尾是.exe。 为了运行生成的可执行文件,我们只需要简单在系统中命令行中输入下面的命令:
./a.out
这个命令将可执行文件装入计算机的内存呢,然后开始运行其中的指令。 10. 当程序开始运行后,计算机将会按顺序执行程序中的指令。如果程序需要从用户那里接收某些数据(也就是输入),系统将暂时挂起程序,以便用户输入。有时程序也可以开始等待某些事件的发生,如鼠标点击等。程序运行的结果通常输出到一个窗口中,这个窗口被称为终端(console)。有时程序也可以直接输出到系统文件中。
- 如果一切顺利,程序将完成它的工作。如果程序的结果不正确,那么我们需要回过头来重新分析程序,排除程序逻辑错误的过程为调试(debug)。在调试过程中,我们通常需要修改源文件,这时我们还需要重新编译、连接,以生成可执行程序。这个调试过程不断重复,直到程序产生我们所需要的结果。
集成开发环境
我们前面大致介绍了使用 C 语言开发程序的每一个步骤,以及每个阶段需要输入的命令。在现代软件开发环境中,编辑、编译、运行和调试过程通常由单个应用程序控制,这个应用程序被称做集成开发环境(Intergrated Development Environment, IDE)。IDE 通常基于互窗口环境,通过 IDE 我们可以很方便管理大型的软件,在窗口中编辑文件,以及编译、连接、运行、调试你的程序。
在 Mac OS X 操作系统中,Code Warrior 和 XCode 是两个很流行的 IDE。在 Window 操作系统中,Microsoft Visual Studio 是一个非常受欢迎的 IDE。Kylix 则是 Linux 下非常热门的 IDE 工具。
解释型语言
除了编译高级语言程序外,还有另外一种方法,可以分析、执行使用高级语言编写的程序。这种方法不是编译程序,而是对程序进行解释(interpreted)执行,相应所需的程序被称为解释器。解释器不需要独立的编译、连接过程,它一边分析源程序,一边执行这些程序。当采用解释执行方法的时候,程序调试起来要容器一些,但是解释执行的程序通常比编译执行的程序要慢,因为编译型语言在执行程序之前,已经预先将程序中的指令翻译成机器指令。
Basic 和 Java 是解释型高级语言的两个例子。Unix 的 shell 和 python 也是解释型的语言。有些软件商也提供 C 语言的解释器。